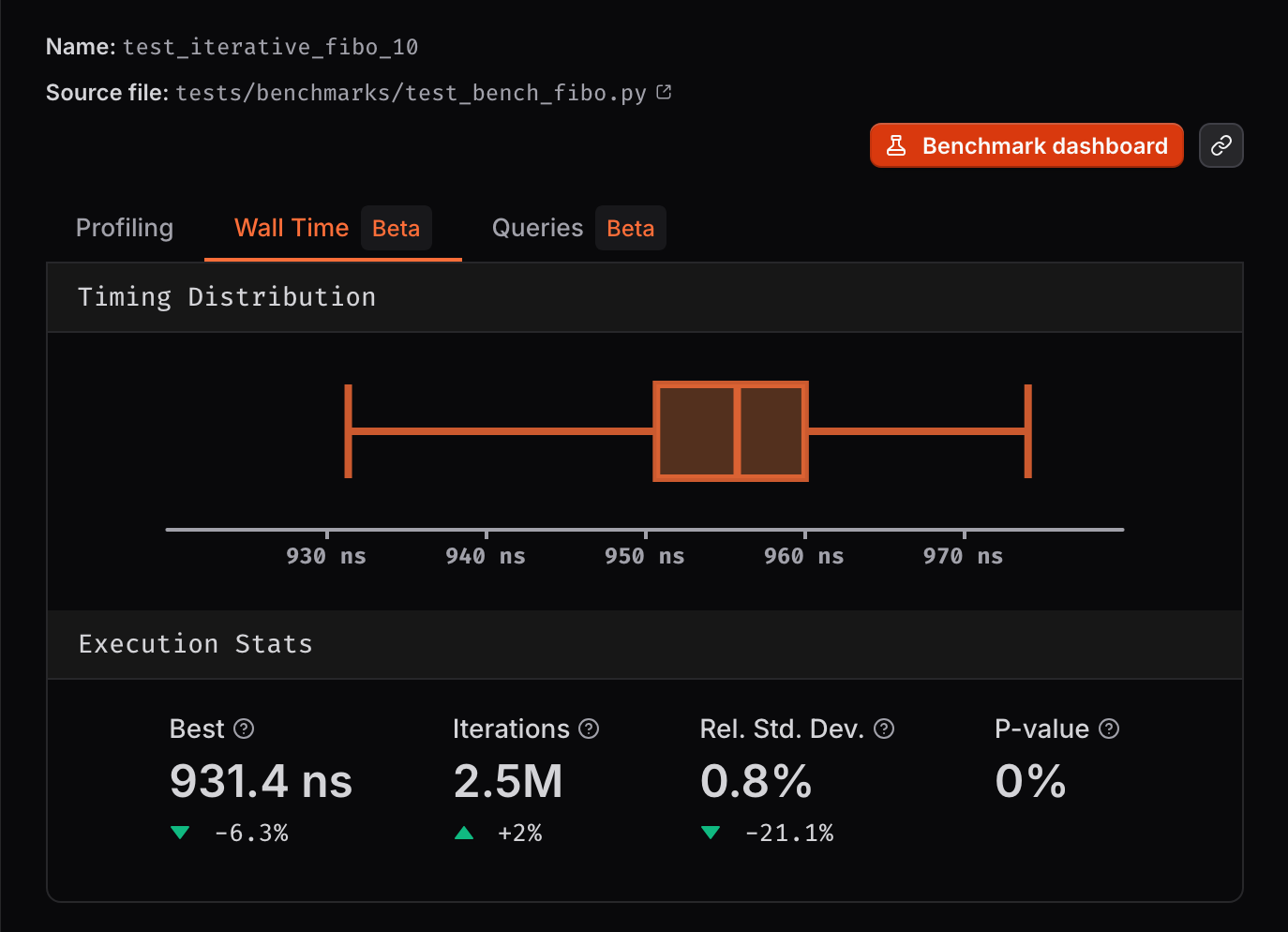
Example of a walltime benchmark run
Supported languages and integrationsAt the moment, the walltime instrument is supported for the following languages
and integrations:
- Python:
pytest-codspeed >= 3.0.0 - Rust
- C++:
codspeed-google-benchmark >= 1.0.0 - Node.js
- Go:
codspeed-go >= 0.3.0
What Does the Walltime Instrument Measure?
The walltime instrument measures the actual elapsed time (also known as “wall clock time”) of your benchmark execution. Unlike CPU simulation which measures simulated CPU cycles, walltime captures the real-world duration including:- All code execution: Both user-space code and system calls are included in the measurement, giving you a complete picture of actual runtime performance.
- I/O operations: Network requests, file system operations, and other I/O bound tasks are fully captured, making this instrument ideal for benchmarks that interact with external systems.
- Parallelism effects: Multi-threaded code benefits are accurately measured since walltime reflects the actual elapsed time, not CPU time across threads.
Multiple benchmark processesWith the walltime instrument, you should try and avoid running multiple
benchmark processes in parallel since this can lead to noisy measurements.Thus, using
pytest-xdist or similar tools is not recommended.Automated Profiling
When using the walltime instrument, CodSpeed automatically collects profiling data and generates flame graphs for each benchmark. This allows you to quickly identify performance changes and their root causes.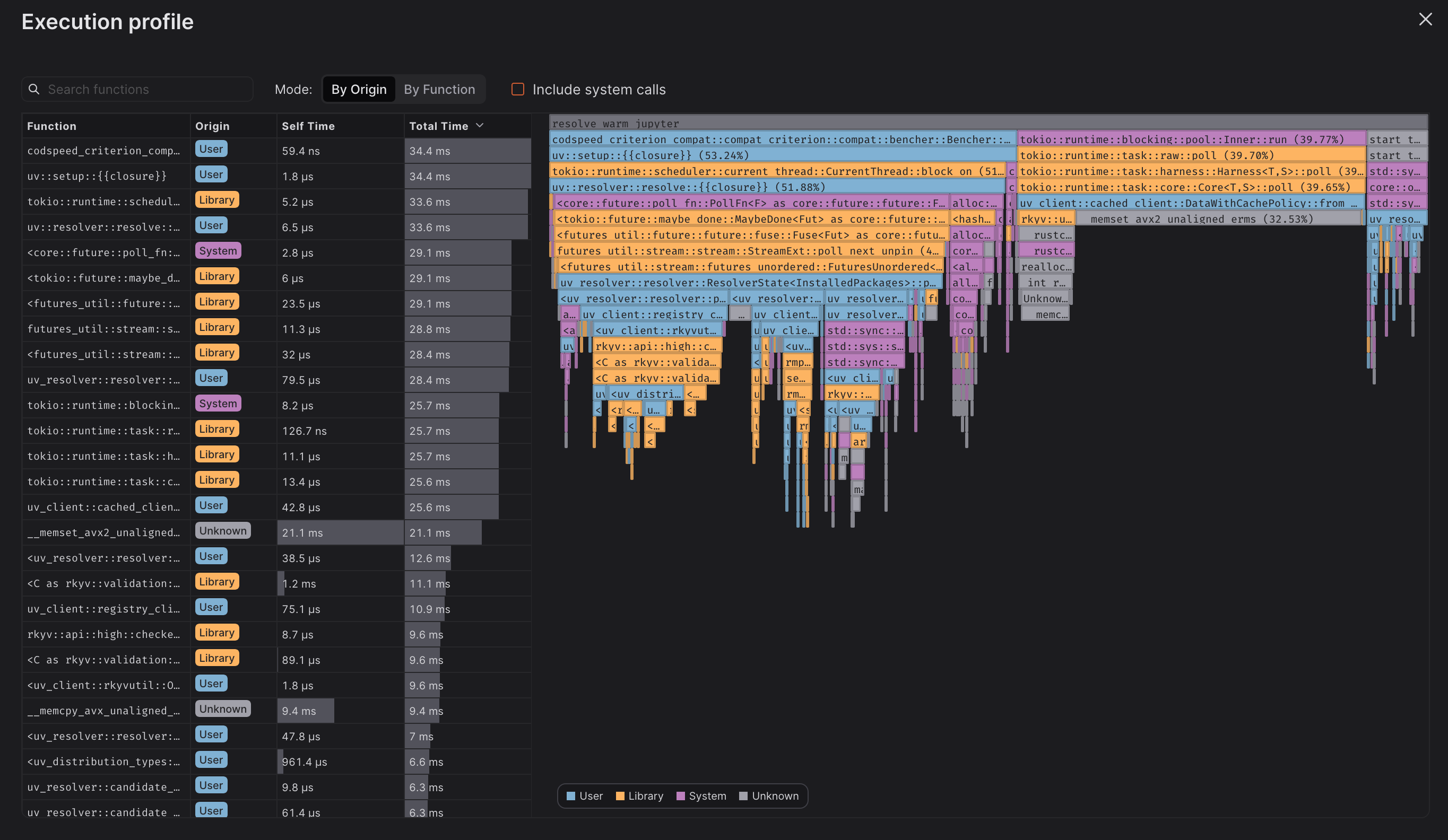
Inspector Metrics
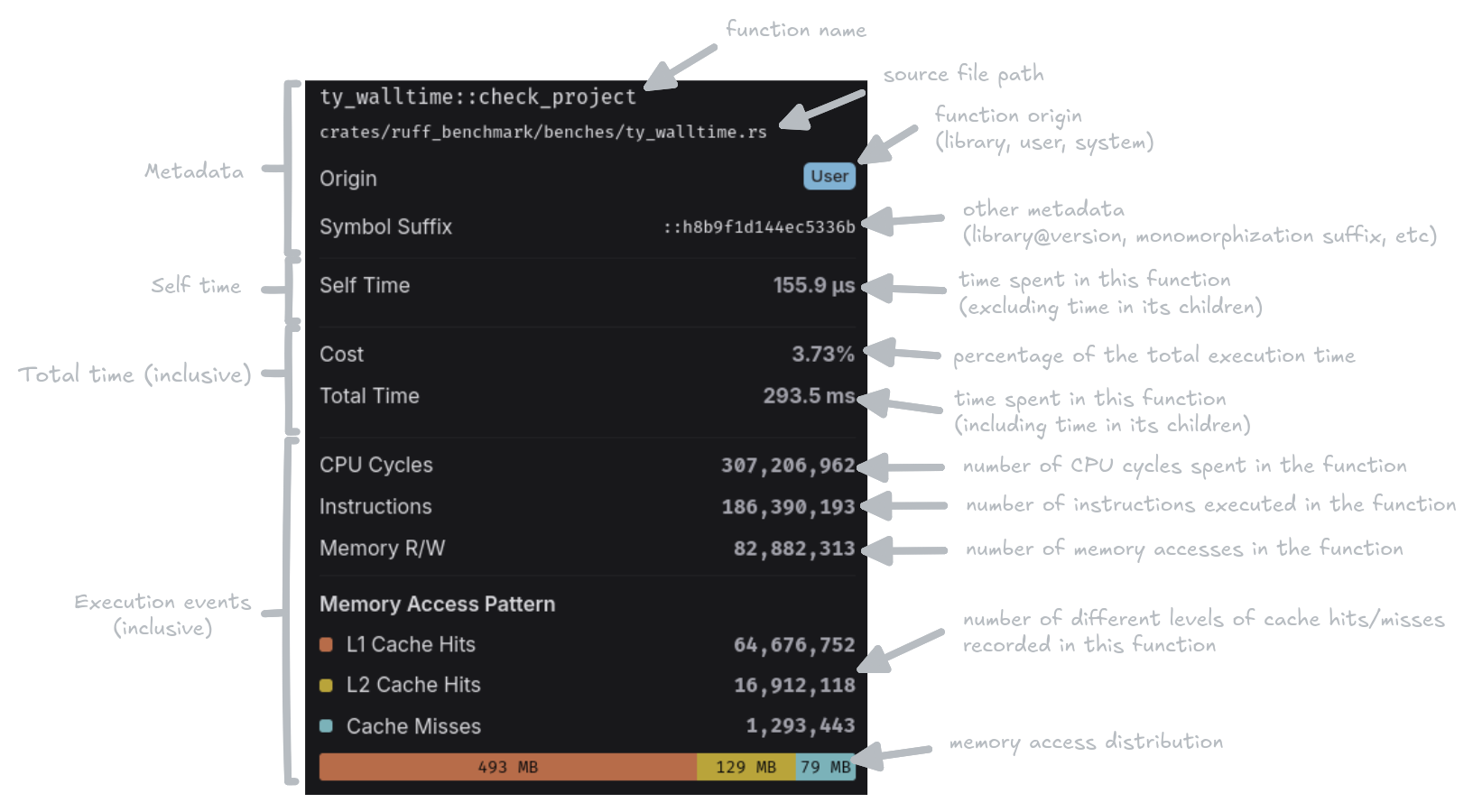
- Self time: The measured execution time spent in the function body only, excluding time spent in child function calls.
- Total time: The measured execution time spent in the function including all its children.
- CPU Cycles: The number of CPU cycles elapsed.
- Instructions: The number of CPU instructions executed.
- Memory R/W: The number of memory read and write operations performed.
- Memory Access Pattern: A breakdown of how memory accesses were served:
- L1 Cache Hits: Memory accesses served from the fastest CPU cache.
- L2 Cache Hits: Memory accesses served from the second-level cache.
- Cache Misses: Memory accesses that required fetching from main memory.
- Memory access distribution: Total bytes read from and written to memory, for each level of cache. It is calculated based on the number of events, and the average size of each access, namely a word for a cache access, and a cache line for a cache miss.
Sampling accuracyEvent counts are collected using hardware performance counter sampling. The
deeper you navigate into leaf functions, the more susceptible these counts
suffer from to sampling-related inaccuracies. For the most reliable data, focus
on higher-level functions in the call stack.
Usage with GitHub Actions
Requirements:CodSpeedHQ/action >= 3.1.0
runs-on: ubuntu-latest
line with runs-on: codspeed-macro and use the mode: walltime option in the
action:
Your benchmarks will now run on a CodSpeed-managed runner, the action and the
benchmark integration will automatically collect walltime data and you’ll be
able to see the new measurements in the CodSpeed dashboard.
Usage on personal GitHub accounts
At the moment, the macro runners are only available for organizations and not for personal accounts. This is because registering GitHub self-hosted runners on repositories instead of organizations would require the Repository: Administration (Read/Write) permission, which is too broad. To use the macro runners on a repository owned by a personal GitHub account, the only solution is to create a new organization and transfer the repository to that organization.Usage on public repositories
By default, the macro runners are only available for the private repositories of your organization. If you want to use them on a public repository, you’ll need to explicitly allow them from your GitHub organization settings (under Organization Settings > Actions > Runner groups > Default).
Next Steps
Macro Runners
Learn more about CodSpeed managed bare-metal runners designed for Walltime
benchmarks
Profiling
Learn more about automated profiling for Walltime benchmarks
Profiling on macOS
Learn why system processes are missing from macOS profiles and how to work
around it