Rust 1.78: Performance Impact of the 128-bit Memory Alignment Fix

The Rust 1.78.0 version was released on May 2, 2024. The
release announcement
mentions that the bundled LLVM version is upgraded to 18, completing the
announced u128/i128
change for x86
architectures. It is mentioned that if your code uses 128-bit integers, you
may notice runtime performance improvement. Let's dive into how this can
happen.
The alignment issue with u128/i128
The alignment of a value specifies what addresses are valid to store the value at. A value of alignment
nmust only be stored at an address that is a multiple ofn(from the the Rust Reference)

Normally, the memory size of a value should always be a multiple of its alignment to prevent misalignment issues.
However, on x86 architectures, there is an inconsistency with the alignment of 128-bit integers between rustc (the rust compiler) and C conventions:
| Data type | Memory size | Alignment |
|---|---|---|
| i128 (rustc 1.77.0) | 16 bytes | 8 bytes |
| __int128 (clang 17.0.1) | 16 bytes | 16 bytes |
In Rust < 1.77, 128-bit integers are 8-byte aligned, whereas the corresponding C types are 16-byte aligned. But they all have a size of 16 bytes.
Let's see how this misalignment can degrade performance.
Why memory misalignment can lead to worse performance?
Having a memory size greater than its alignment can lead to cases where the value is stored at an address right at the edge of a memory cache line (which is usually 64 bytes), which will cause the value to be stored on two cache lines instead of one.
Let's create an example where this happens with Rust 1.76.0 on an x86_64 machine. Let's look at the following code:
use type_layout::TypeLayout;
const GAP: usize = 128;
#[derive(TypeLayout, Copy, Clone)]
#[repr(C)]
struct StockAlignment {
_offset: [u8; GAP - 8], // 1-byte aligned
data: u128, // 8-byte aligned
}
pub fn main() {
println!("Alignment of u128: {}", align_of::<u128>());
println!("{}", StockAlignment::type_layout());
}Here, we created a StockAlignment struct that contains an array _offset of
u8 and an u128 integer data. We use the
type_layout crate to be
able to see what the size and alignment of the struct will be.
After we execute the code, we have the following:
Alignment of u128: 8
StockAlignment (size 136, alignment 8)
| Offset | Name | Size |
| ------ | --------- | ---- |
| 0 | _offset | 120 |
| 120 | data | 16 |That means that an instance of StockAlignment will span three cache lines of
64 bytes, like so:
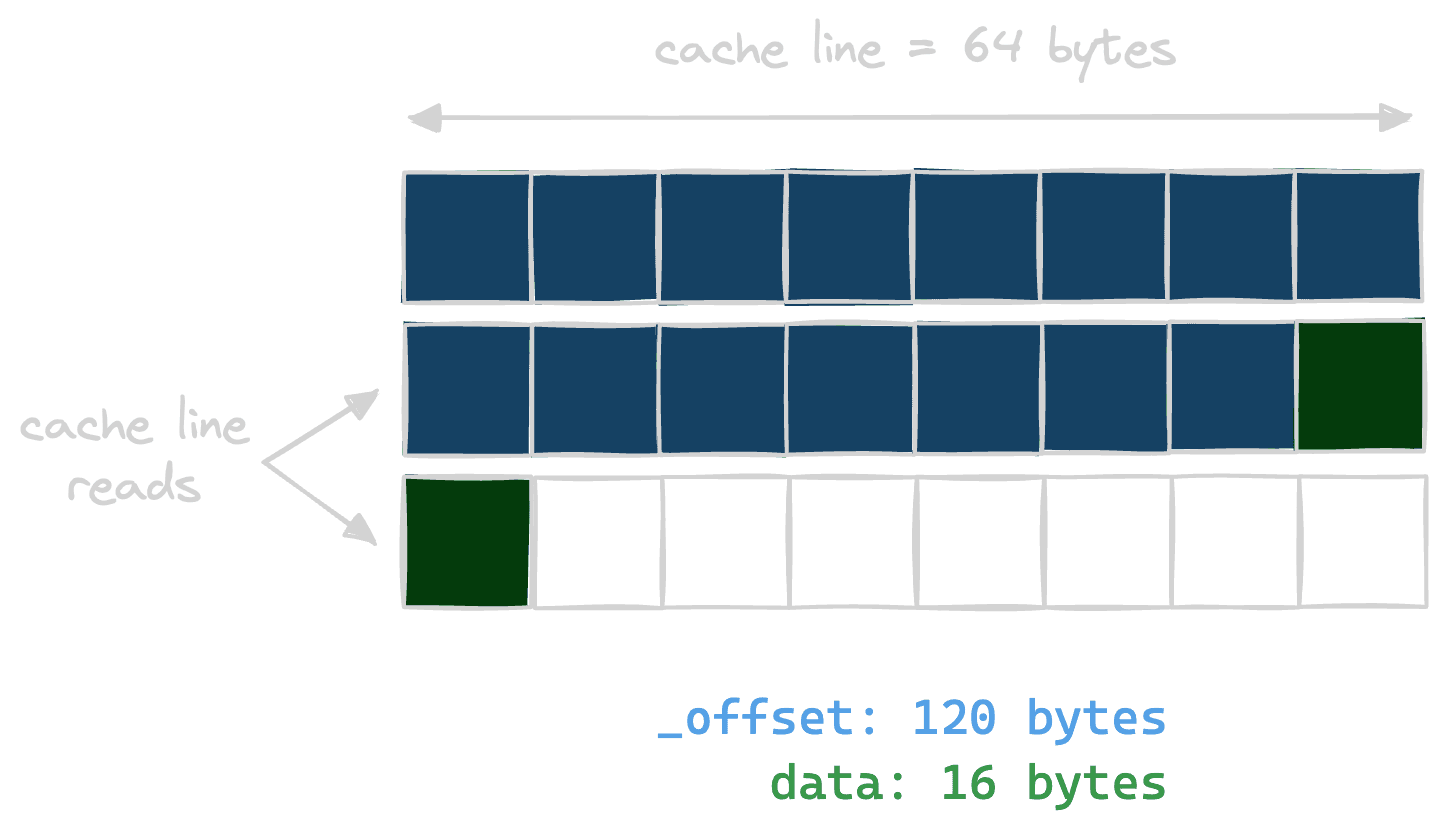
The misalignment problem is visible here. When data is accessed, two cache
lines of 64 bytes are read from memory. This is effectively loading twice as
much data as needed, since data is only 16 bytes, a single cache line could
have been read if it was properly aligned.
Let's create a new struct where we enforce data and its containing struct to
be correctly (16-bit) aligned. With the proper alignment, this is what we expect
the memory layout will look like:
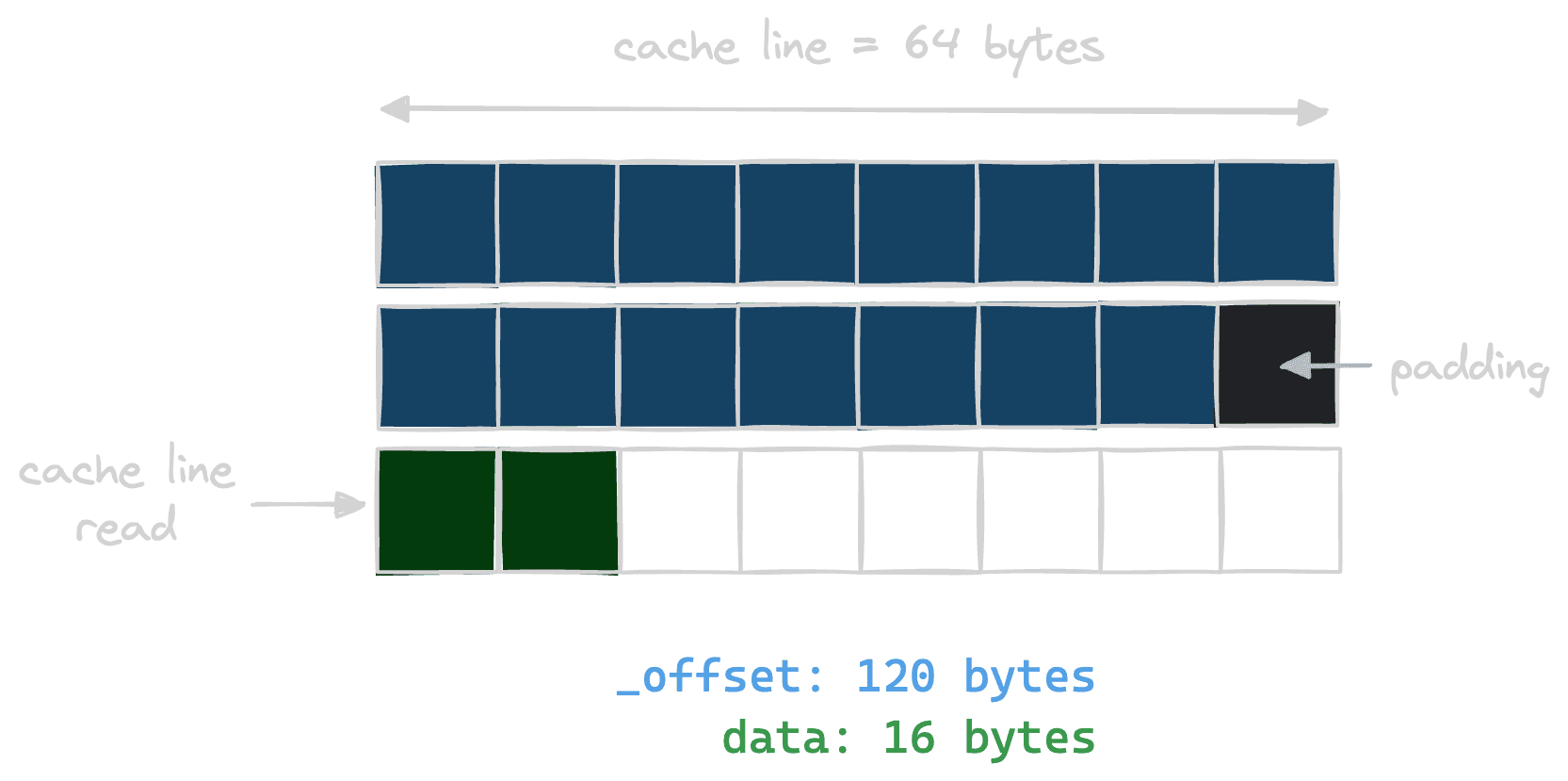
With that alignment, accessing data will only load a single cache line. To
achieve it, we can write the following code:
use type_layout::TypeLayout;
const GAP: usize = 128;
#[derive(Copy, Clone)]
#[repr(C, align(16))]
struct AlignedU128(u128);
#[derive(TypeLayout, Copy, Clone)]
#[repr(C)]
struct EnforcedAlignment {
_offset: [u8; GAP - 8],
data: AlignedU128,
}
pub fn main() {
println!("{}", EnforcedAlignment::type_layout());
}Here we created a struct AlignedU128, that only stores a single u128 and
enforce it to be 16-byte aligned. We then use this as the type of data in a
new EnforcedAlignment struct.
After we execute the code, we have the following:
EnforcedAlignment (size 144, alignment 16)
| Offset | Name | Size |
| ------ | --------- | ---- |
| 0 | _offset | 120 |
| 120 | [padding] | 8 |
| 128 | data | 16 |So we optimized EnforcedAlignment to access data more efficiently, but it
comes at a cost in memory since it costs 8 more bytes than StockAlignment.
Comparing the performance between the two alignments
To measure the performance of loading data with different alignments, we
created performance tests with the
criterion.rs benchmarking library.
Before running the benchmarks, we allocate two arrays of 8192 elements, one
filled with StockAlignment instances, and the other one with
EnforcedAlignement. We then create two benchmarks where we access the data
property of all the elements of the array:
let c: &mut Criterion;
let stock_align: Vec<StockAlignment>;
c.bench_function("stock align bench", |b| {
b.iter_batched(
cache_fuzzer,
|_| {
let mut sum = 0;
for i in 0..N {
sum += stock_aligned[i].data;
}
sum
},
criterion::BatchSize::PerIteration,
);
});For the other struct, we have the same benchmark code.
The iter_batched
function
allows to pass a setup function as the first argument, with the actual benchmark being the second
argument. The cache_fuzzer function is used to clear the cache before each benchmark to avoid
the effect of cache hits on the benchmark results. This ensures that previous iterations have
close to no impact on the current one.
To have stable and reproducible results, we use the CodSpeed runner, providing a consistent execution environment.
This notable performance improvement when using the properly aligned struct confirms our initial idea: optimizing the alignment effectively reduces the number of cache misses and thus RAM accesses, ending up with a positive impact on performance.
Here we only tested when accessing elements of the array in an ordered way. Under the hood, there could be some optimizations loading more memory than requested from contiguous blocks in our measurements. For example, loading more memory than requested from contiguous blocks. To test in different situations, we added two more groups of benchmarks:
reversed access, to simulate access in a reversed orderrandomized access, to simulate access in a randomized order
We get the following results:
The performance gains are consistent with the first we observed and thus the order in which we access the data does not affect the performance much.
Using the CodSpeed runner will execute the benchmark code on a virtualized CPU in a controlled CI environment, measuring the CPU instructions and turning them back into a human-readable time measurement. Learn more about the CodSpeed performance metric on our docs.
Real-world check with Rust 1.78.0
Now that we identified and shown the problem with Rust 1.76.0, let's bump Rust to 1.78.0 and see what happens.
// rust-toolchain.toml
[toolchain]
channel = "1.76.0"
channel = "1.78.0"Let's check the alignment of our previous misaligned struct:
Alignment of u128: 16 <-- was 8 before
StockAlignment (size 144, alignment 16) <-- size was 136 before, alignment was 8
| Offset | Name | Size |
| ------ | --------- | ---- |
| 0 | _offset | 120 |
| 120 | [padding] | 8 | <-- new
| 128 | data | 16 | <-- properly aligned nowThe inconsistency has indeed been solved. The performance of stock align
increased by 10% and is now equal to enforced align since the alignments
are the same.

A note on 1.77
Although it was not announced in the release blog post, the 128-bit integers misalignment fix was already included as a part of the 1.77.0 release. The reason it was announced later is that there was a related bug linked to 128-bit integers arguments which was only solved with the update to LLVM 18 completed with the 1.78.0 release.
Check out the CodSpeed report of the pull request, where the performance gain is already visible.
Performance gains from bumping to 1.78.0 in the ecosystem
We have seen a number of repositories gaining performance increases when upgrading the toolchain from 1.77.x to 1.78.0, with performance gains up to 21% depending on the benchmark. Those performance changes are not solely due to the alignment fix, but most probably related to optimizations released with the new LLVM version.


Takeaways
Making sure our data structures have a proper memory alignment does improves performance by reducing cache misses and making memory accesses faster. However, it comes with a higher memory footprint implied by the padding added within our memory layouts.
These small performance changes can be hard and tedious to track, but this is where we can leverage performance testing continuously in CI environments, enabling informed optimization decisions.
Here is the repository containing the code shown in this article and you can also find its CodSpeed performance dashboard here.